Introduction
剽窃やプロパガンダなどにLLMの生成された文章が使われる。なので、LLM生成の文章と人間生成の文章の検出をしたい。
だが先行研究では限られたドメイン関連や、限られたモデルにのみ通用する手法がほとんどであった。だが実際の検出の現場では生成するモデルも知らないし、関連する分野のドメインも不明である。
この研究は
- 既存の検出手法は、実世界での応用で考えたときにちゃんと区別できるか?
- 各ドメインの文章の間に、人間の生成したテキストとLLMの生成したものの間にドメインに固有の区別はあるか?
これらについて、様々なタスクについてLLMでの生成を考え、大きなテストベッドを構築した。
これで実験を行い、いくらOut of Distributionを考慮して訓練させた識別器でも、見たことのないドメインでの人間の書いたドキュメントの実に62%をLLM製と誤って判断してしまう。
だが、これはドメイン内のわずか0.1%のデータをを用いて学習させるだけで、誤判断率をめちゃくちゃ下げられる。
Related Work
- 先行研究では、言語モデル生成の文章の識別ではn-gram頻度、エントロピーの値、当惑度、負の曲率領域などがある。しかし、これらは基本的にwhite boxでの応用である。
- Black boxでの応用では、ほとんどは特定のドメインに絞ったものである。
データセットの構築
「意見文」、「ニュース記事」、「質問と回答」、「ストーリー生成」、「常識からの推論」、「知識図」、「科学論文」の7つのタスクについての、生成された文章の検出を目指す。
LLMは27種類もの大量のものを使った。
プロンプトについては
- 人間が書いた書き出し(30 words前後)について、続きを生成してもらうようにする。
- 指定のトピックを与えて、そのトピックについて書いてもらう。
- テキストソースを指定(BBCニュースを使えとか)して、特定のトピックについて書いてもらう。
検出システム
PLMやLongFormer, GTLR, FastTextを使う。
Experiments
実験の設定
以下の8個の設定について実験した。
- 人間の書く文書: 固定のトピック領域。生成するLLM: 固定のLLM。
- 人間の書く文書: 任意のトピック領域。生成するLLM: 固定のLLM。
- 人間の書く文書: 固定のトピック領域。生成するLLM: 任意のLLM。
- 人間の書く文書: 任意のトピック領域。生成するLLM: 任意のLLM。
- 分類器が学習データで見たことないLLMによる生成の検出。
- 分類器が学習データで見たことないドメインについての生成の検出。
- 分類器が学習データで見たことないLLM+ドメインについての生成の検出。
- 見たことのないLLM+ドメインについて、人間の書く文書とLLM生成した文書を、機械的なルールに従って言いかえする。
結果
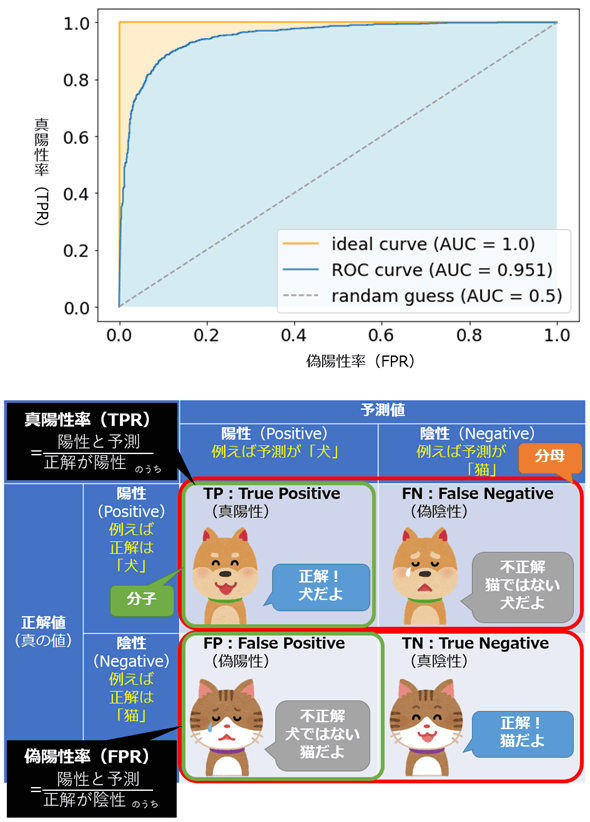
- 評価指標はAUROCである。以下のようなもの。
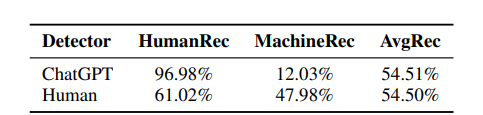
これは通常のChatGPTと人間のアノテーターの識別能力。ランダムより少し良いだけ。
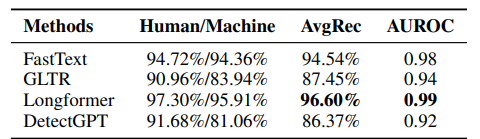
特定のドメイン、特定のLLMを指定すると非常に高い性能があるとわかる。